"To understand something, write about it," they say. I'm curious. So I started writing: first on my personal blog, mostly about data vis when I got into the field around 2014. There was so much to learn! Since November 2017, I get paid by Datawrapper to do just that: Figuring things out, and taking you all on a tour with me. These are my best articles from both eras:
Hi! My name is Lisa  .
.
I create, talk & write about data vis, currently for Datawrapper in Berlin. Here I show what I've worked on in the past few years.

February 2021
A data vis crossword puzzle!
Find the 13 vis types, 5 tools, 14 people, and 22 concepts from the field of data vis and win a data vis book.

September 2020
on Datawrapper ↗
How to pick more beautiful colors for your data visualizations
Common color mistakes and how to avoid them

October 2018
One Chart, Nine Tools – Revisited
2.5 years ago I recreated the same chart with 24 different charting tools. It's time to revisit some of them.
March 2018
on Datawrapper ↗
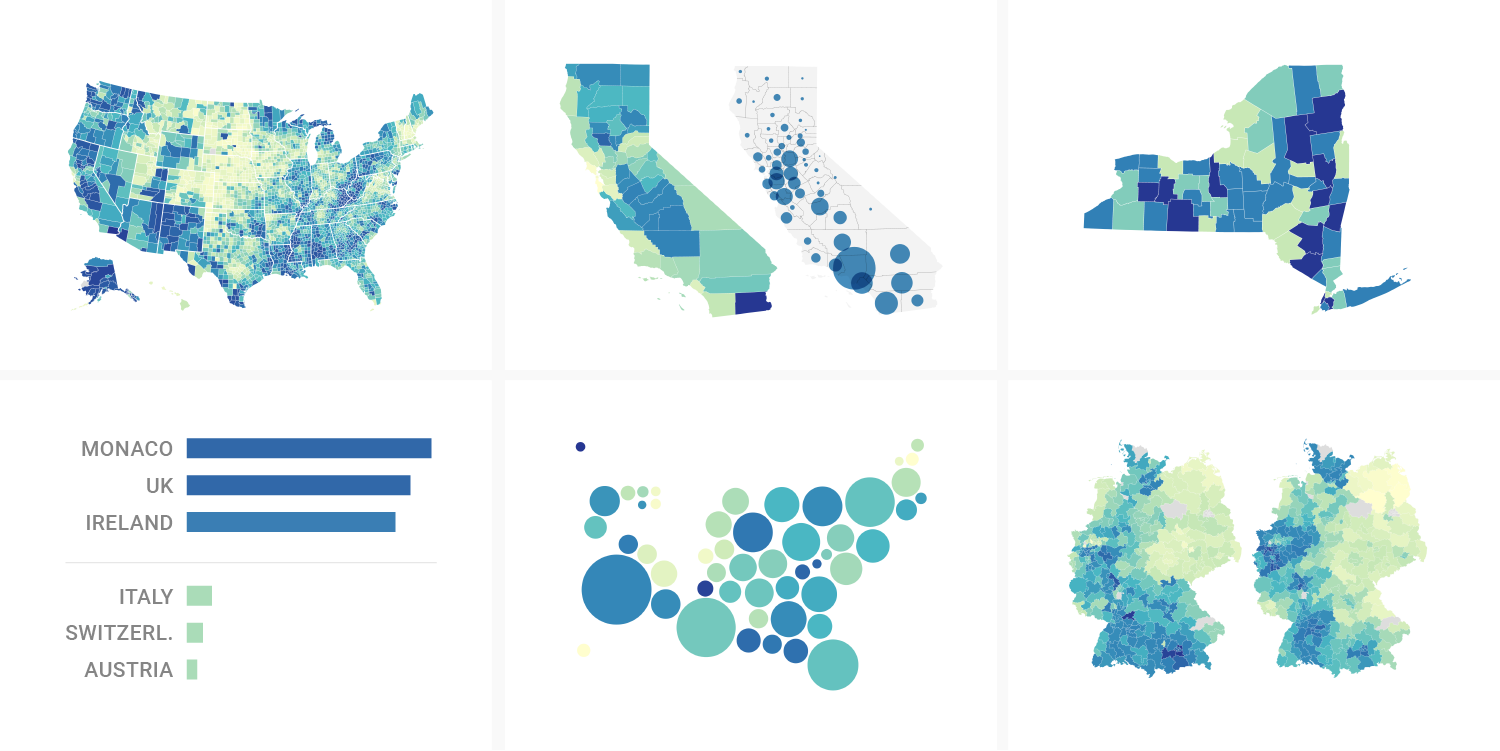
What to consider when creating choropleth maps
What to map, how to map and whether or not to use a map in the first place.
April 2017
Embracing Curiosity
Finding the sweet spot between discovery and explanation.
September 2016
How I Feel When I Learn To Code
Aaaall the feels: Pride, Panic, Despair, Overwhelm, Annoyance.
April 2016
Map vs. Territory
"Everything simple is false. Everything which is complex is unusable." – Paul Valéry
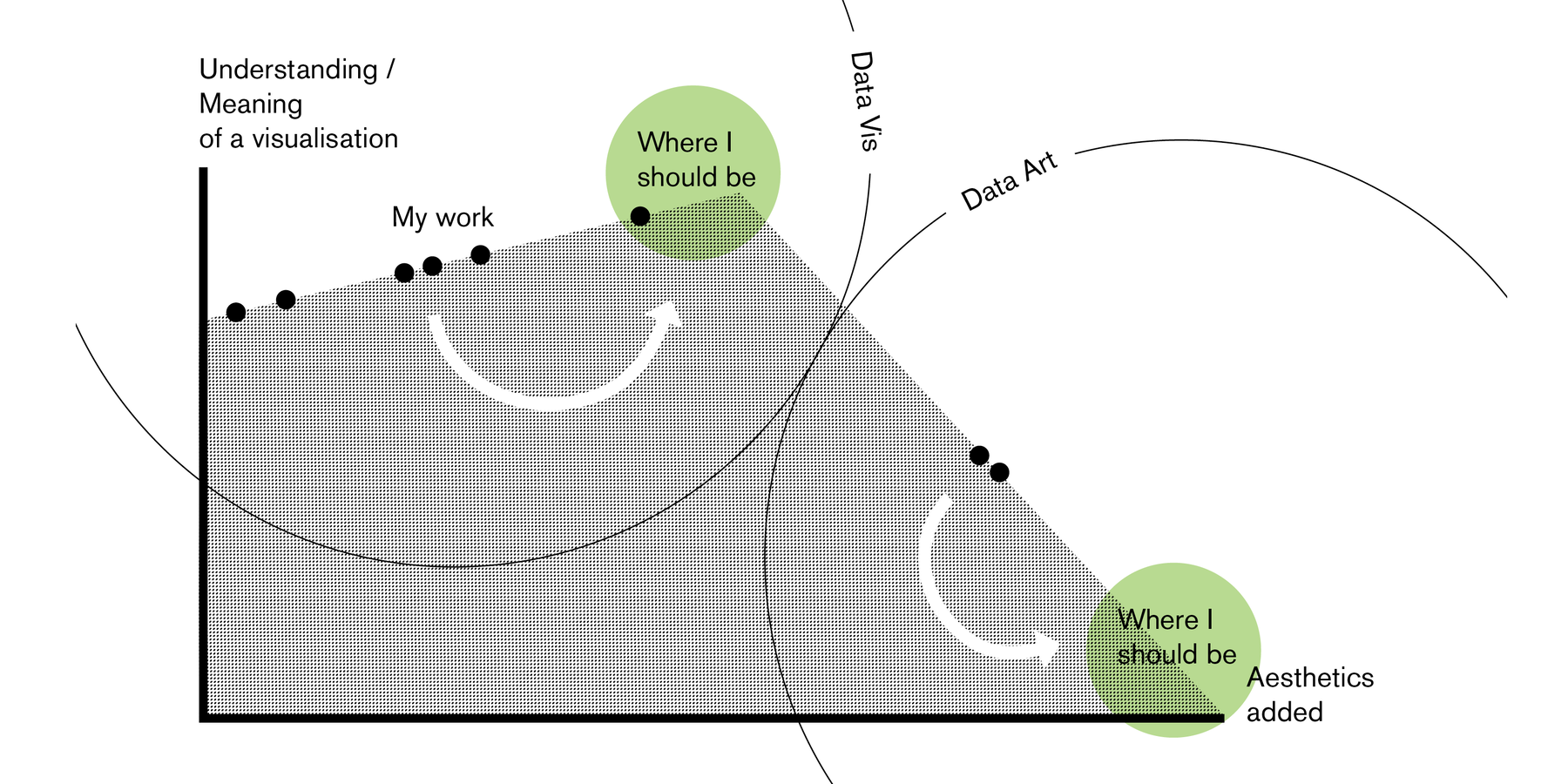
December 2015
Meaning + Beauty in Data Vis and Data Art
In Data Vis, we should see aesthetics as a tool to increase understanding. In Data Art, we can see aesthetics as the purpose.
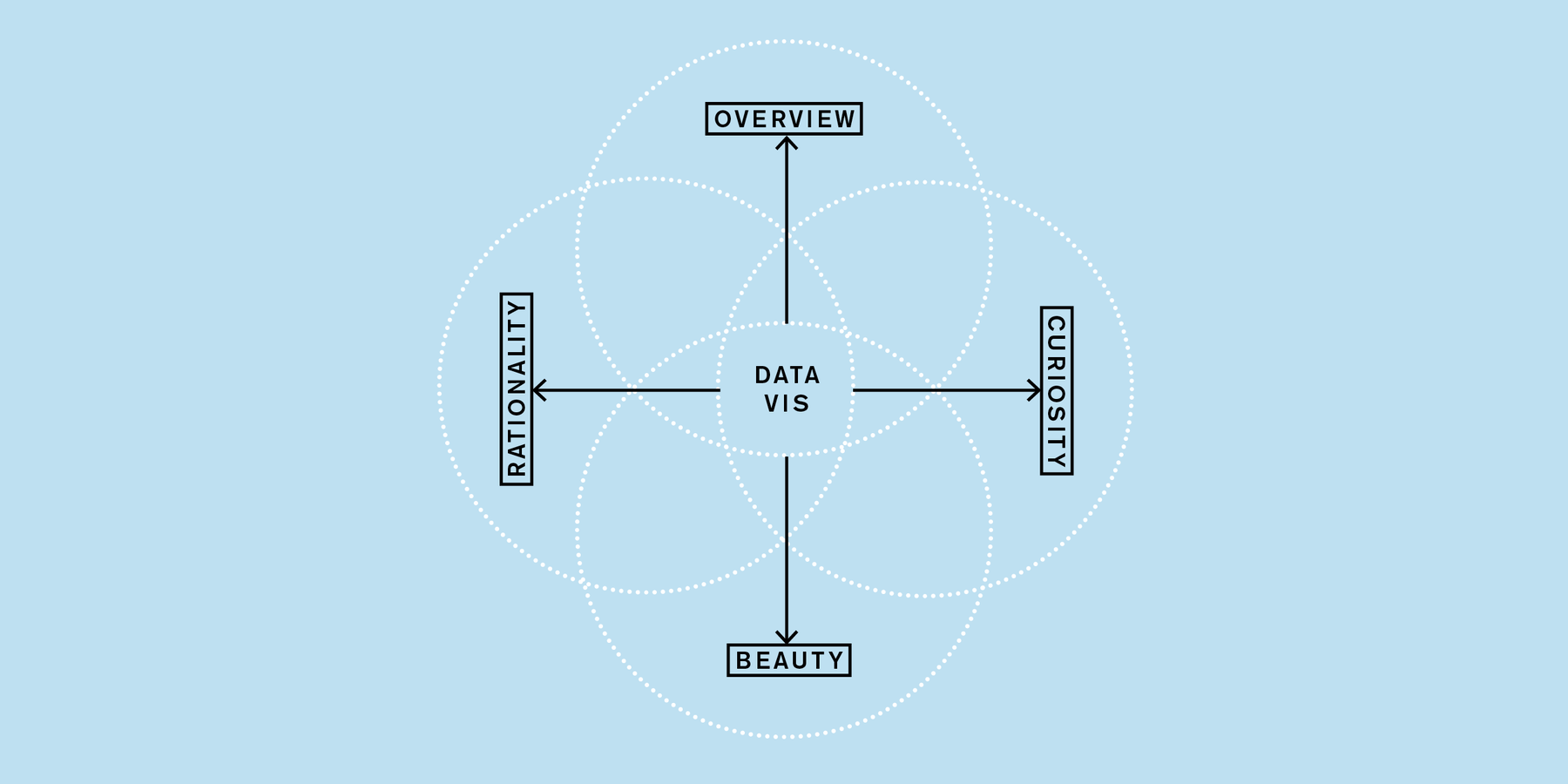
January 2015
Personality Traits for a Data Vis Career
How values like curiosity and a need for overview motivate us to go to meetups to create data vis.
Selected Talks
Talks let me combine images (slides) and text (my speech) in a more tension-building, direct way than blog posts. I taught data vis at different universites and have given general data vis workshops over the years – but here you can find the talks I used as an excuse to research a completely new question:
May 2017
at Republica
Why We Don't Believe In Facts, And How To Fix That
It's not about truth vs lie, it's about them vs us. Plus some data vis that made me think.

March 2017
at INCH
Why do we visualize data?
Categorising the different reasons for visualizing data, and looking at examples & different industries on the way.

December 2016
at CCC & OpenVisConf
A Data Point Walks Into a Bar
"If I look at the mass I will never act. If I look at the one, I will." A look at data (vis) vs anecdotes.

October 2016
at NACIS
Map Poetry
Drawing our internal maps lets us explore how we and others see the world.
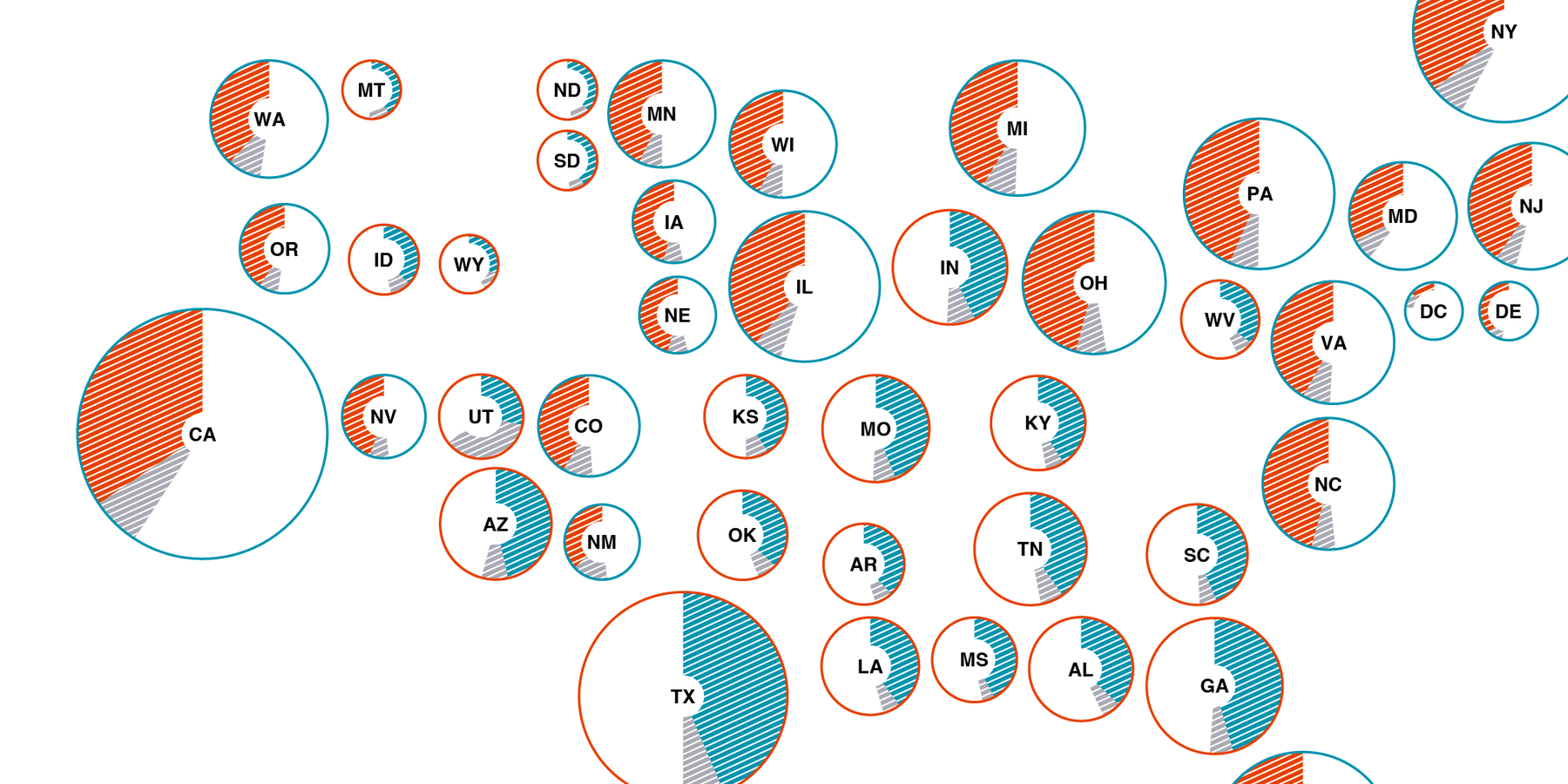
October 2016
at the GeoNYC Meetup
Making Election Maps Popular Again
Why we should map the popular votes, even in US elections.

June 2016
at Information+
Less News, More Context
"With which information can my audience navigate this world better?" Looking at goals of journalism, and how data vis fits in.
Selected Projects
Before delving into data vis, I studied print design for six years. These are some of older student works (still data vis related-ish), and newer ones I've created for newsrooms or my blog. You can also find some charts I've created during my time at Datawrapper:
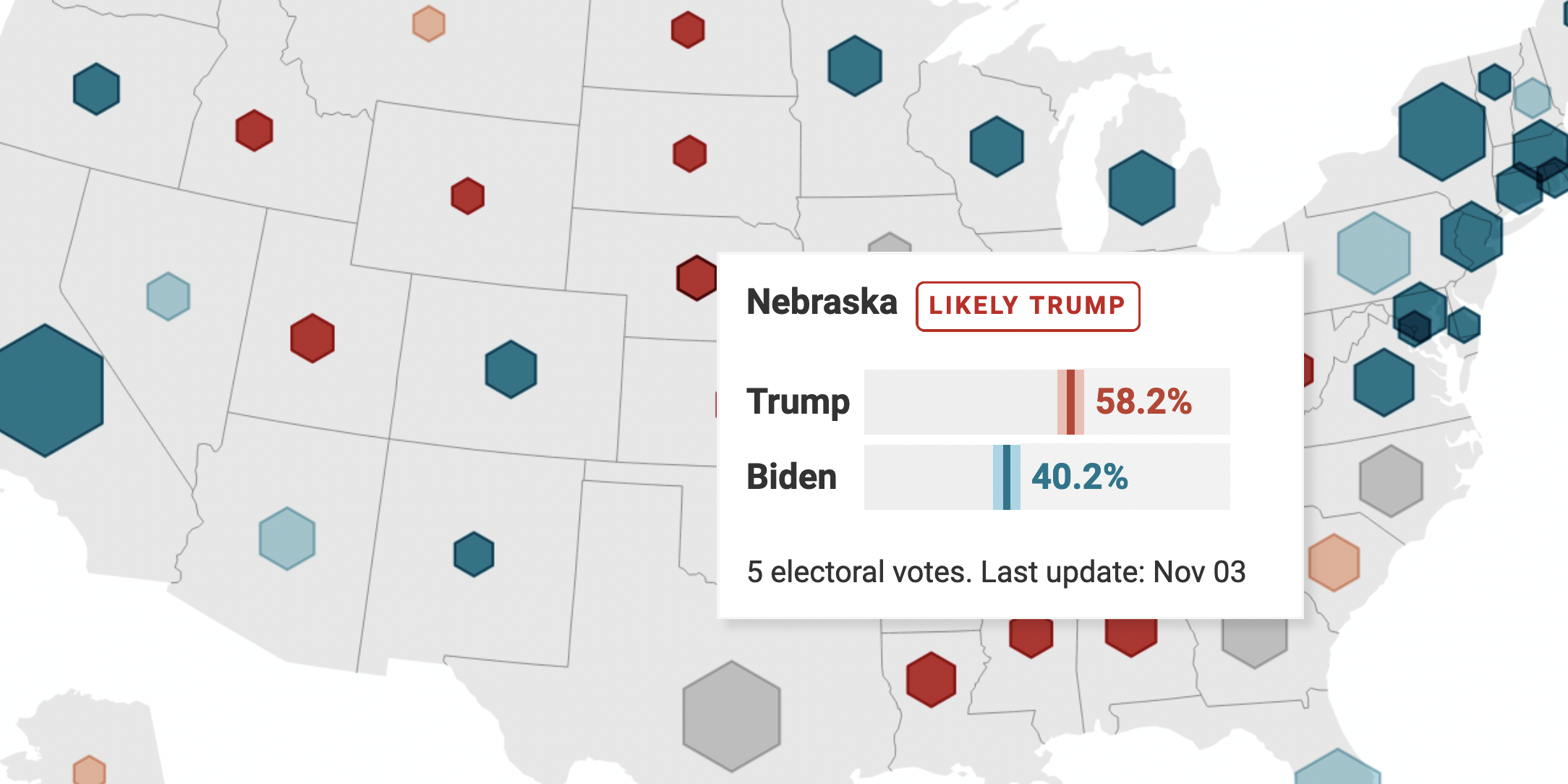
2020
for Datawrapper
Datawrapper visualizations I created in 2020
2020 was packed with corona charts. Besides that: US elections, university degrees, public holidays, and lots of tooltip charts.

2016
Which Cities Are On Similar Latitudes?
A simple visualization that removes data to let us see more.

2016
for SPIEGEL
Back then, everything was worse.
Illustrating a weekly graphic for a column in the German magazine DER SPIEGEL.
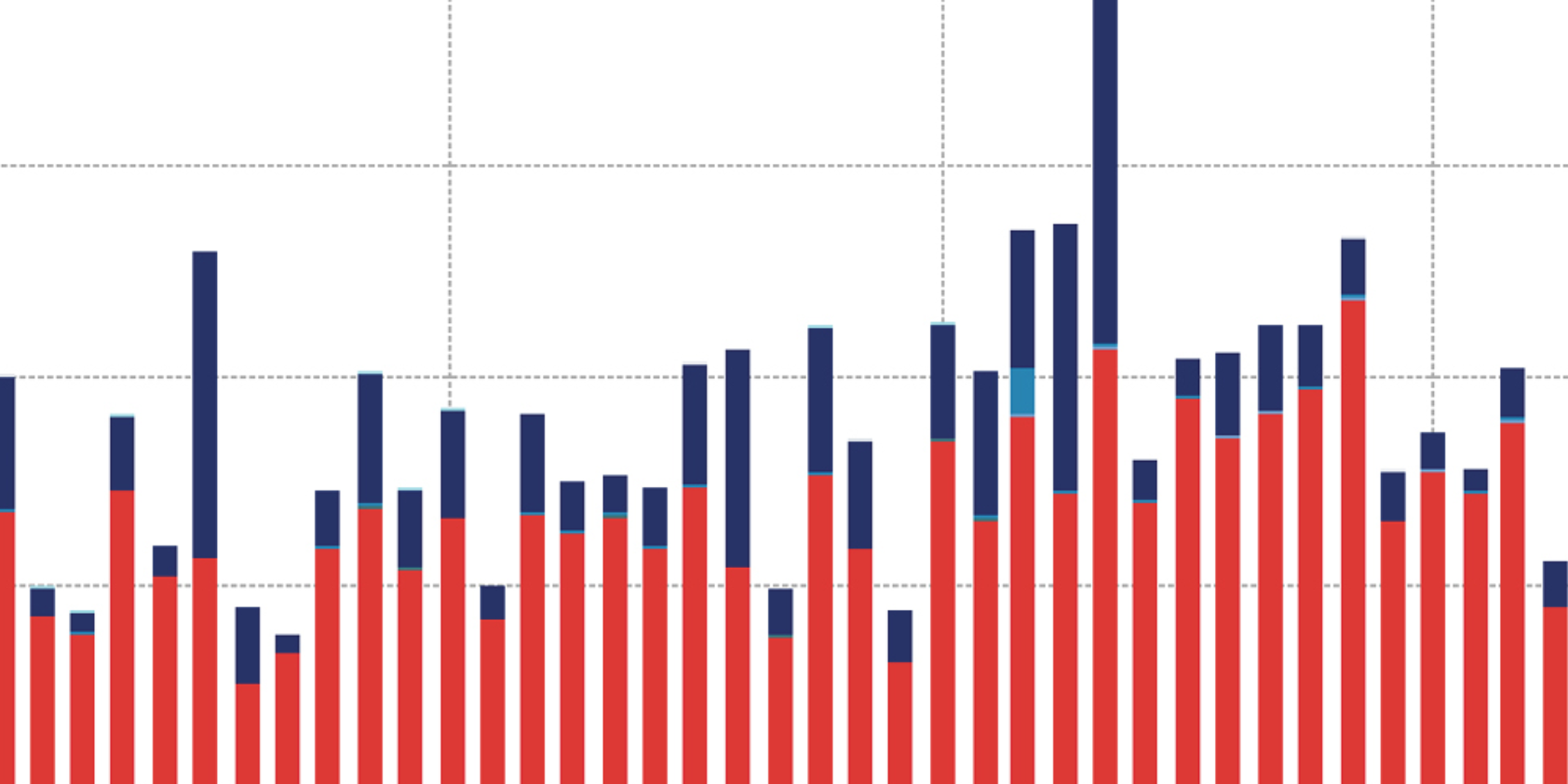
2015
My Google Search History – visualized
I visualized the 40,000 search queries I asked Google between June 2010 and April 2015.
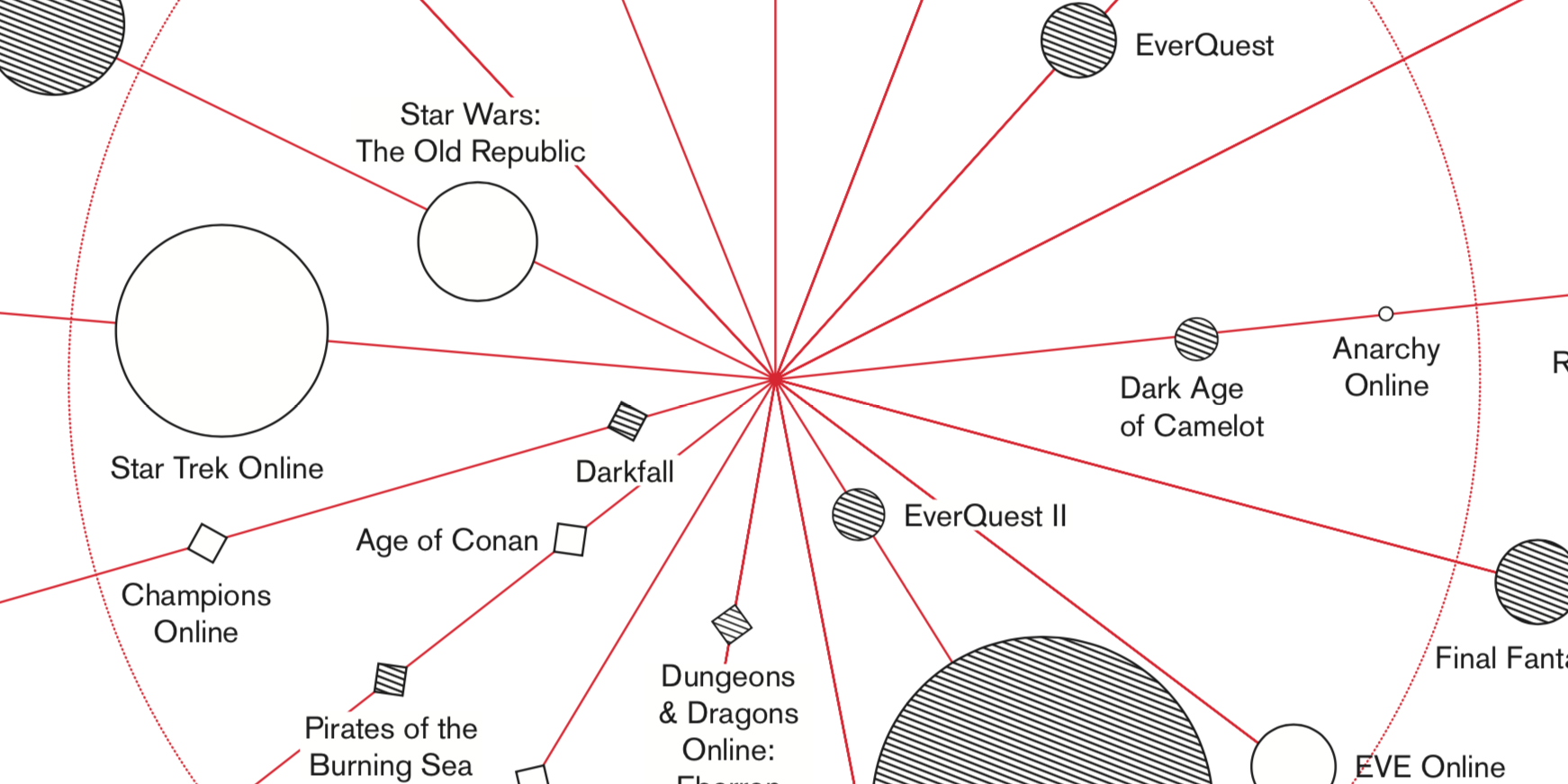
2014
Data Vis in my Master's Thesis
During my master's thesis, I redesigned three magazines in three different styles. Here are the pages that involve the best infographics.
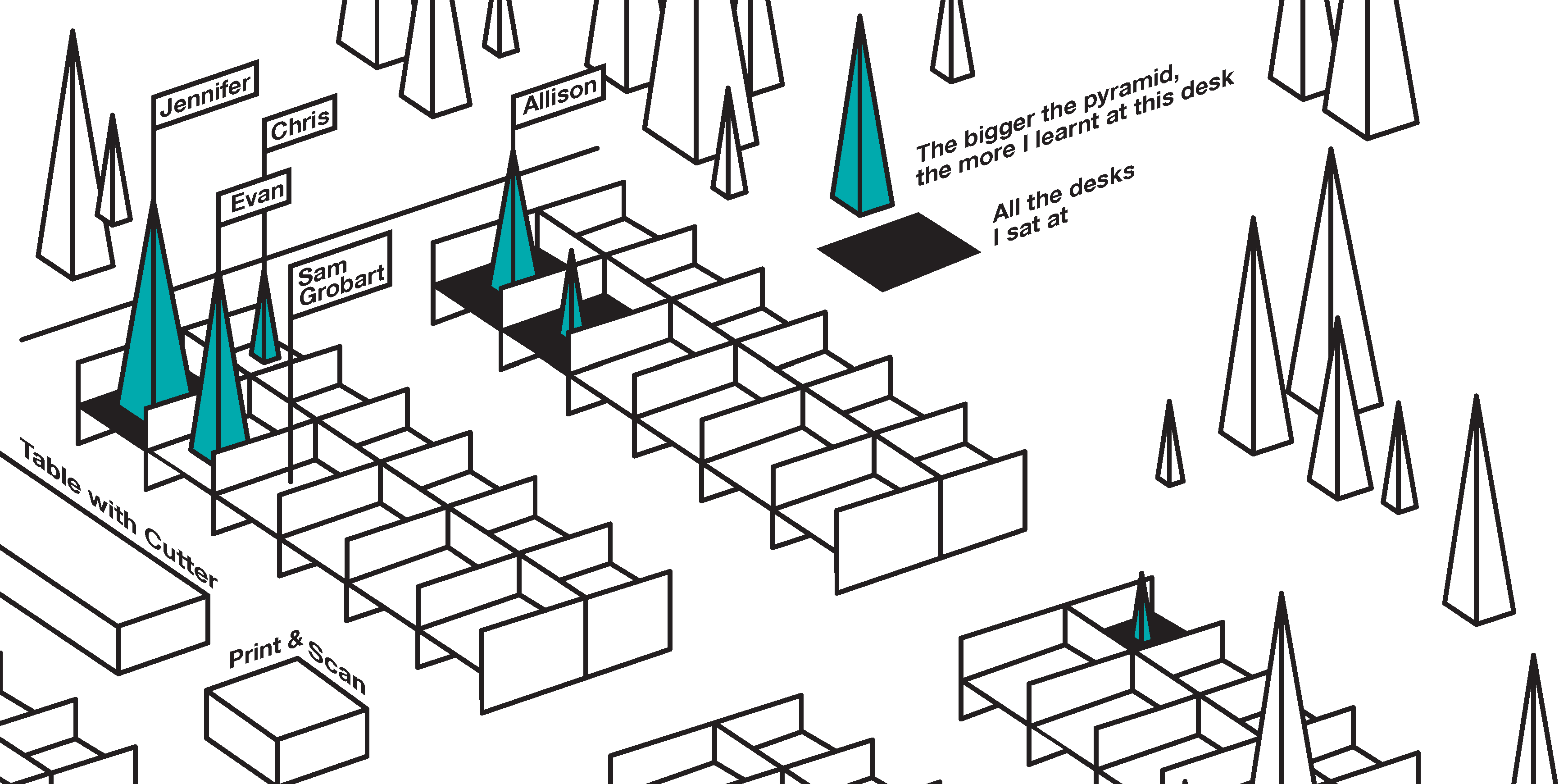
2013
Documentation of my internship at Bloomberg Businessweek
In spring 2013, I spent eleven wonderful weeks as an intern at the Bloomberg Businessweek in New York City.
About me
Lisa Charlotte Muth is a Berlin-based writer for the data visualization tool Datawrapper. Before that, she studied graphic design for six years and created data visualizations for newsrooms like Tagesspiegel, Bloomberg, SPIEGEL, ZEIT Online, and NPR as an OpenNews Fellow. She co-hosted the Berlin Data Vis meetup, started the global, digital Data Vis Book Club, writes a handbook, and tries to live a good life.